Strategische Fehlersuche im Active Directory
15. Februar 2011
Exchange, Sharepoint, der SQL Server oder das Active Directory (AD) – all diese Applikationen haben einen eigenen Satz von Vorgehensweisen, wenn es sich um die Fehlerbehebung dreht. Für den Administrator gehört es zum täglichen Brot, Fehler zu diagnostizieren und sie letztendlich – meist sogar unter großem Zeitdruck – zu beheben. Auf einer hohen Abstraktionsebene folgen aber alle Fehlerbehebungsversuche demselben Muster. Doch leider verwenden viele Systembetreuer diese Methodik nicht konsequent genug. Resultat: Sie verbringen zu viel Zeit mit der Problemlösung.
Wer dagegen die grundlegenden Prozeduren zur Fehlerbehebung kennt und verstanden hat, der wird seinen Job mit weniger Aufwand betreiben können. Es muss weitaus weniger Zeit damit verbringen, sich die passenden Lösungen für die Probleme zu erarbeiten. In diesem Beitrag wird eine professionelle und wissenschaftlich fundierte Vorgehensweise gezeigt und dann diese Erkenntnisse im Rahmen der Fehlersuche beim AD eingesetzt.
Das Beherrschen der Fehlersuche gehört für einen Administrator zum wichtigsten Können im technischen Bereich. Üblicherweise erlernt er es Stück für Stück – meist von einem erfahrenen Kollegen aus dem IT-Team. Es kommt nur ganz selten vor, dass ein Systembetreuer ein professionelles Training bekommt, in dem er in die Grundlagen der strukturierten Problemlösung eingearbeitet wird.
Deswegen setzt ein Administrator üblicherweise eine Vielzahl von verschiedenen Tools ein und kommt dann zu einem einigermaßen strukturierten Vorgehen im Zuge der Fehlersuche und -behebung. Doch das Modell ist nicht sonderlich vertrauenserweckend: Wir lassen einen Schwung Werkzeuge auf das Problem los und hoffen oftmals, dass das eine oder andere unser Problem löst. Ein ingenieurmäßiges Vorgehen sieht dagegen anders aus.
Die Basis für ein zuverlässiges Modell für die Fehlerbehebung setzt eine Methodik voraus, die einem zur korrekten Lösung führt. Diese Methodik gilt es gottseidank nicht neu zu erfinden – die wissenschaftliche Methodik ist bereits erarbeitet, und lässt sich auch gut dafür einsetzen.
Nun wird nahezu jeder Administrator von sich behaupten, dass ein derartiges Verfahren bereits verwendet. Er spekuliert, wie das Problem genau lautet und testet dann seine Hypothese. Danach erfolgt der Test, ob diese Aktion das Problem wirklich gelöst hat. Wenn das nicht der Fall ist, wird sozusagen in der Schleife wieder zum Anfang gegangen und die nächste Hypothese aufgestellt und überprüft. Wer diesen Ansatz bereits verfolgt – und das werden nicht wenige sein—der kennt auch den Nachteil: Man löst quasi einen Schuss aus, trifft der ist alles gut, wenn nicht, geht es wieder von vorne los. Doch eine effektive Methodik zur Fehlersuche ist weitaus präziser und detaillierter als dieser eher oberflächliche Ansatz.
Bei Cisco hat man sich die Arbeit gemacht und ein achtstufiges Netzwerk-Fehlerbehebungsmodell erstellt, das hier noch eine Adaption durch den Autor aufgrund seines IT-Know-how erfahren hat. Die einzelnen Schritte, die hier folgen, sollen in erster Linie als ein roter Faden im Bereich der effektiven Fehlerbehebung dienen.
Genaue Definition des Problems
Im ersten Schritt geht es immer darum, das Problem möglichst genau zu skizzieren. Dabei gilt es alle Ungenauigkeiten in der Fehlerbeschreibung zu vermeiden. Zum Beispiel sollte eine Fehlermeldung nicht lauten: „DC1 repliziert nicht korrekt.“ Diese ungenaue Aussage impliziert, dass der DC1 die Aktualisierungen nicht von allen übergeordneten DCs holt und dass die nachgeordneten DCs von ihm Aktualisierungen bekommen.
Dagegen kann das genau umrissene Problem viel kleiner sein, etwa. „Der DC1 erhält keine Aktualisierungen von der Konfigurations-Partition des DC2.“ Generell gesagt: Eine hohe Präzision schlägt unqualifizierte Annahmen aus dem Feld, ehe sie sich auswirken können.
Soviel detaillierte Informationen wie möglich abfragen
Hier sind Fragen zu stellen wie: „Was funktioniert nicht?“, „Was funktioniert noch?“, „Was hat sich geändert gegenüber dem Zeitpunkt als alles noch funktionierte?“ Wenn es sich um ein Problem auf einem Client handelt: „Haben auch andere Clients dieses Problem?“ Wenn ja: „Was haben diese Clients gemeinsam?“, „Verwenden sie dieselbe Build-Version des Betriebssystems?“, „Liegen sie alle im selben Subnetz?“, „Verwenden sie alle denselben Applikationsserver?“, „Ist bei diesem System irgendetwas besonders?“.
Wenn es sich um einen Server handelt: „Liegt er hinter einer Firewall?“ Wenn ja: „Haben irgendwelche anderen Server dieselben Symptome?“
Mögliche Ursachen für den Fehler bestimmen
Dabei handelt es sich um die kritische Phase in dem gesamten Prozess. Beim Überlegen und dem Erstellen einer Hypothese, warum es zum Fehler gekommen ist, besteht eine massive Abhängigkeit, welche Applikation ein Problem hat. In komplexen Software-Konstrukten wie etwa dem Active Directory (AD) gibt es hunderte von möglichen Fehlerquellen für ein Problem. Daher gilt es immer, die Ursachen soweit möglich einzugrenzen.
Dabei ist eine Regel zu beachten: Meist ist die einfachste Lösungsmöglichkeit auch diejenige, die passt. Doch darauf kann man sich auch nicht immer verlassen. Den oftmals ist die erste, zweite oder gar die dritte Option passt – falls das ursprüngliche Problem eine andere Ursache hat als eigentlich angenommen wurde.
Hier kommt ein weiterer Lösungsansatz ins Spiel, die „Fehlersuche von ganz unten“. Üblicherweise hängt die Komponente mit dem Fehler von weiteren Infrastruktur-Bestandteilen ab. Daher sollte sich die Fehlersuche auch an dem Netzwerkmodell der OSI (Open Systems Interconnect) ausrichten. Moderne verteilte Systeme setzen auf einem derartigen Modell auf.
Daher empfiehlt sich ein Vorgehen, das auf der untersten Ebene, dem Physical Layer, beginnt und sich dann nach oben bis zur Applikation durcharbeitet. Im Fall einer verteilten Anwendung, wie das beim AD der Fall ist, sind die einzelnen Abschnitte das physikalische Netzwerk, die namen-zur-IP-Adress-Auflösung, das Server-Betriebssystem. Diese untergeordneten Schichten sind zuerst zu prüfen, ehe man sich an das AD macht. Wenn der Administrator seine Annahmen testet, sollten diese Überlegungen auch so gefasst sein, dass die untergeordneten Schichten auch wie erwartet funktionieren.Die besondere Eleganz für diesen Ansatz liegt darin begründet, dass er sich für alle vernetzten Systeme eignet.
Für einfachere Probleme wird dagegen dieses Vorgehen eher überdimensioniert sein. Wenn der Administrator über eine Remote-Verbindung mit einem Server kommuniziert, dann ist bereits sicher, dass der Server eingeschaltet ist und dass die Netzwerkverbindung – zumindest für einige Ports – funktioniert. Damit lassen sich dann einige Schritte im Bereich der unteren Ebenen eliminieren.
Doch der Systembetreuer sollte sich immer genau notieren, welche er dabei schon ausgeschlossen hat, ehe er sich dem nächsten Bereich widmet. Der nächste und übernächste Schritt folgen dann oft in einem iterativen Modus. Dabei tragen die neu gewonnenen Erkenntnisse dazu bei, die Hypothese neu zu fassen und sie zielgerichteter abzufassen.
Testplan für die Hypothese ausarbeiten
Bei der Planung der Tests sollte man immer das nächste Prinzip verfolgen, selbst wenn es noch so eilig ist, den Fehler zu beheben: Immer nur eine Variable ändern und dann erneut testen. Geht der Administrator dazu über, mehrere Parameter von einem Test zum anderen zu ändern, lässt sich keine genaue Aussage treffen, welche Variable für die Verbesserung des Zustand verantwortlich ist.
Angenommen Server A kann keine Session mit Server B eingehen und wenn man dann auf beiden Systemen Änderungen in den Netzwerkeinstellungen vornimmt, dann weiß man nicht was genau falsch war. Es wird zwar in einigen Fällen erforderlich sein, dass entweder die betreffende Situation oder aber der Vorgesetzte einen dazu zwingen, mehr als eine Änderung in einer Iterationsstufe auszuführen, doch dann muss man sich bewusst sein, dass eine exakte Definition des Fehlers nicht stattfinden kann.
Den Plan implementieren
Wenn es sich irgendwie einrichten lässt, sollte man das Testen zusammen mit einem Kollegen oder einem Auditor durchgehen. Es gibt kaum etwas besseres, wenn ein zweiter Spezialist sich die Informationen ansieht und dann eventuell feststellt, dass man etwas übersehen hat. Komplexere Pläne sollten immer mit entsprechendem zeitlichen Vorlauf durchdacht und dokumentiert werden.
Danach muss man sich allerdings auch exakt daran halten. Der oftmals praktizierte Schnellschuss kann dagegen zu ungültigen Resultaten führen, mit der Folge, dass ein vollkommen falscher Lösungsweg eingeschlagen wird.
Ergebnisse der Implementierung überwachen
Hat die Vorgehensweise zu einer Fehlerlösung geführt? Und wenn nicht: Wurde den überhaupt das Verhalten des Problems damit geändert?
Vorgang ab dem dritten Schritt wiederholen
Dabei gilt es dann, die nächst bessere Hypothese zu überprüfen, wenn es zu keiner finale Problemlösung gekommen ist. Hier ist wieder zu beachten, dass man sich in den voneinander abhängigen Netzwerkschichten nach oben durcharbeiten sollte.
Ist es zum Beispiel ein Problem mit Sharepoint, muss man auch testen, ob der SQL Server korrekt funktioniert. Ist es die Replikation zwischen zwei Domänencontrollern, ist zu testen, ob es überhaupt eine Netzwerkverbindung zwischen den beiden Systemen gibt.
Die gemachten Änderungen dokumentieren
Ist das Problem erst einmal gelöst, sollte eine nachträgliche Durchsicht des gesamten Fehlerbehebungsprozesses erfolgen. Dabei sind Fragen zu stellen wie: Kam es zu einer schnellen und geradlinigen Lösung oder war man zuerst vollkommen “Land unter”?
Im letzteren Fall ist zu überprüfen, warum der eigentliche Grund für den Fehler so schwer zu finden war. Dann ist man in der Lage, die eigene Vorgehensweise bei der nächsten Fehlersuche entsprechend zu optimieren. Bei der nachträglichen Betrachtung muss man keine umfangreichen und formalin Aspekte beachten – außer es handelt sich um einen extrem großen Fehler mit vielfältigen Auswirkungen. Was dagegen zählt ist eine Verbesserung des Fehlersuchprozesses, damit sich ein ähnlicher Fehler nicht wieder zu einer so enormen Aufgabe auswächst.
Strukturierte Fehlersuche im Active Directory
Die zuvor erwähnte Fehlersuchmethodik mit ihren acht Schritten passt für eine Vielzahl von Situationen – nicht nur im IT-Bereich. Im weiteren Verlauf dieses Beitrags soll anhand der Fehlersuche im AD gezeigt werden, wie sich diese Vorgehensweise mit den geeigneten Tools kombinieren lässt.
Beim AD handelt es sich um eine sehr komplexe Middleware, die auf anderen recht komplexen Komponenten aufsetzt. Dabei ist zuerst die Frage anzugehen, welche anderen abhängigen Bestandteile gut funktionieren müssen, damit das AD korrekt arbeitet.
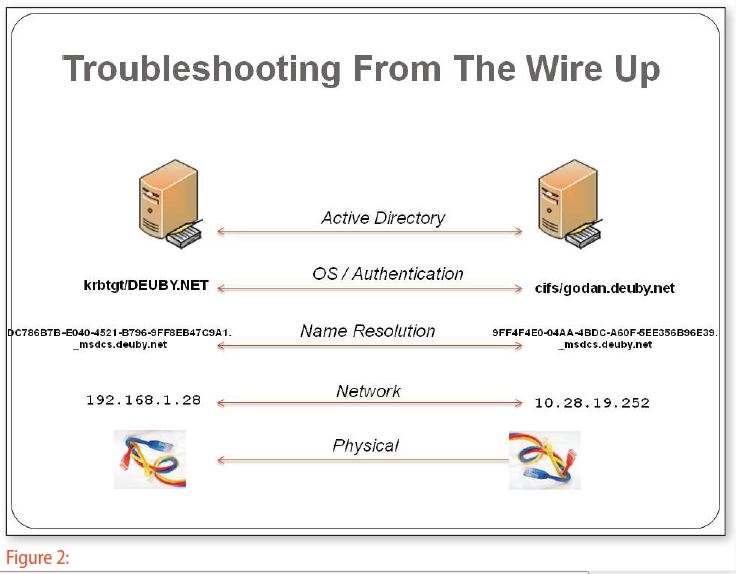
In der Abbildung 2 sind die Architekturebenen zu sehen, die für das AD besonders wichtig sind: Die physikalische Vernetzung (die Verkabelung plus die Stromzufuhr), das IP-Netzwerk, die Namensauflösung (DNS, Domain Name System), das Betriebssystem, die Komponenten für die Authentifizierung und schließlich das AD selbst.
Die physikalische Ebene ist schnell geklärt: Ohne Strom funktioniert nichts, und wenn die Netzwerkkabel nicht eingesteckt sind, lassen sich keine Datenpakete übertragen. Doch es darf nicht aus der Gleichung genommen werden, denn es gab zumindest beim Autor unzählige Supportfälle, in denen aus den eher lapidaren Gründen – wie etwa weil ein gesamter Standort im AD während der Feiertage ausgeschaltet war und die IT-Mitarbeiter in der Niederlassung in der Zentrale nicht Bescheid gegeben haben. Bereich fallen auch noch die Hardware-Ausfälle eines Domänencontrollers.In diesen
Im Bereich des Netzwerk-Layers gilt es die IP-Adresse oder die Subnetzkonfiguration auf Fehler zu überprüfen. Aber auch Ausfälle des WAN oder des LAN oder Änderungen an der Firewall, die bestimmte Ports blockieren, fallen in dieses Segment. Die angesagten Hilfsprogramme auf dieser Ebene sind Ping, Ipconfig und Tracert.
Für die Fehlerbehebung kommt aber auch noch ein ganz anderer, nicht technischer Aspekt ins Spiel: Einzelne Teams, wie etwa die für das Netzwerk zuständigen ITler und die für das AD zuständigen Administratoren, müssen enger miteinander kommunizieren. Damit lassen sich “Nichtinformationszustände” besser vermeiden.
Vor dem AD ist dann auch noch die Namensauflösung zu testen. Hier sind besondere Kenntnisse von Nöten, den hier finden sich die meisten Ursachen für Probleme im AD. Das DNS führt die Auflösung von Hostnamen zu IP-Adressen aus, doch es sind dabei noch einige andere, wichtige Aspekte zu beachten.
Dazu gehört die Festlegung, wo bestimmte Dienste zu finden sind. Werkzeuge in diesem Umfeld sind Nslookup, Nltest, Dcdiag und Ipconfig.
Dann geht es bereits um das Betriebssystem. Auf dedizierten Domänencontrollern erweist sich die Fehlersuche auf der Betriebssystemebene als weniger schwierig, verglichen mit typischen Applikations-Servern. Denn der DC verfügt in der Regel nur über ein minimales Betriebssystem, die AD Domänendienste und das DNS.
Bei Windows 2003 kann der Administrator die Netsh Diag GUI einsetzen und Netdiag. Bei Windows 2008 stehen der Servermanager und der Performance and Reliability Monitor zur Verfügung. Ab dem Release 2 (R2) von Windows Server 2008 kommt noch der Best Practices Analyzer mit dazu. Zudem steht auf allen Server-Versionen auch noch das Ereignisprotokoll zur Verfügung.
Über das Download-Center von Microsoft steht auch noch das Tool MPSReports zur Verfügung. Mit diesem Programm kann man viele Informationen des betreffenden Systems sammeln – ganz so wie das der Support bei Microsoft auch macht. Doch wer das Tool selbst einsetzt, der kann sich auch die Ergebnisse selbst anschauen. Dazu gibt es noch ein entsprechendes Anzeigeprogramm: den MPSReports Viewer (ist ebenfalls als Download von Microsoft verfügbar).
Das Thema Autentifizierung im Bereich des Betriebssystems – heutzutage ist das Kerberos – wird als ein eigenes Kapitel betrachtet. Denn es ist eine sehr häufige Quelle. Oftmals stammen aus diesem Bereich sogar mehr Fehler als aus dem kompletten anderen Teilen des Betriebssystems. Kerberos benötigt eine sehr genaue Zeitsynchronisation. Des weiteren sind ein Ticket-Granting Ticket und ein Session-Ticket nötig, damit man sich an den gewünschten Ressourcen in der Domäne anmelden kann.
Aber auch hier sind Werkzeuge passend, wie etwa Kerbtray und Klist (aus dem Download-Center von Microsoft). Manchmal bezieht sich das Problem gar nicht auf irgendwelche Authentifizierungs-Mechanismen, sondern auf den Einfluss von Mitarbeitern.
Hier spielen auch Zeitumstellungen (Sommerzeit) eine Rolle, wenn es internationale Unternehmen betrifft. Ein derartiger Zeitunterschied führt dazu, dass die Kerberos-Tickets nicht mehr funktionieren. Dann meldet der DC entsprechende Fehler.
Das Lösen von AD-Problemen benötigt all diese Kenntnisse, um die verschiedenen beweglichen Teile in dieser verteilten Applikation so zu isolieren. Ein Administrator, der zu irgendeiner Fehlerbehebung herangezogen wird, kann mit derselben Vorgehensweise alle möglichen Aufgaben – vom weitverzweigten Unternehmens-AD bis hin zum PC der Kinder zuhause – bewältigen. Doch es ist immer ein logischer und stark strukturierter Ansatz nötig. Dann lassen sich alle Situationen recht schnell in den Griff kriegen.