Storage-Flaschenhälse beheben
14. Juli 2016
Wenn IT-Verantwortliche den Umstieg auf Flash-Speichermedien angehen, ergibt sich eine spürbare Verbesserung, denn die Flash-basierten Medien reagieren „vergleichsweise sofort“. Deswegen denken viele IT-Verantwortliche, dass der Umstieg auf All-Flash Arrays ihr Storage-Latency-Problem löst. Und das stimmt auch, wenn man den Blickwinkel „pro Laufwerk“ wählt. Doch bei genauerer Betrachtung verschiebt sich das Latency-Problem nur: Es zeigt sich nicht mehr beim Speichermedium, sondern der Speicher-Controller (üblicherweise im Array) und die darauf laufende Software rückt in den Fokus. Hier bringt die Parallelisierung große Verbesserungspotenziale.
Anwendungen im Unternehmenseinsatz decken vielfältige Bereiche ab. Es gibt kleine „Helferlein“, die dem Anwender bestimmte Teilaufgaben erleichtern aber auch unglaublich große Datenbanken, die im Backend eines Unternehmens als Datendrehscheibe fungieren. Doch alle Applikationen haben eines gemein: Die Reaktionszeit muss sehr kurz sein – anders ausgedrückt: Ein Anwender, Kunde oder Interessent, der zu lange auf die Reaktion „des Systems“ warten muss, wird sich woanders um den gewünschten Service umsehen. Damit wird die Reaktionszeit einer Applikation zu einem extrem wichtigen Faktor für die Akzeptanz der Anwender und letztendlich sogar für den Geschäftserfolg.
In den meisten IT-Umgebungen liegen die prinzipiellen Gründe für die unerwünscht langen Wartezeiten in der Datenspeicher-Infrastruktur. Daher rangiert das Thema „Verbessern der Speicherinfrastruktur“ bei den meisten IT-Verantwortlichen ganz oben auf der Agenda. Doch bei den Anbietern von Storage-Systemen kommen häufig Wertigkeiten ins Spiel, die nicht das eigentliche Problem im vollen Umfang betreffen: Heutzutage wird besonderes Augenmerk auf die IOPS (Input/Output Operations Per Second) gelegt, die Auswirkungen der Verzögerungszeit (Latency) dagegen gerät oftmals in den Hintergrund.
In der Realität sind es sogar drei bestimmende Parameter, wenn man Aussagen zum Durchsatz einer Storage-Architektur treffen muss: IOPS, die Latency sowie die Bandbreite. IOPS und meist auch die Bandbreite sind Parameter, die diskutiert werden, die Latency aber bekommt in der Regel zu wenig Aufmerksamkeit. Doch sie erweist sich in vielen Fällen als der wichtigste Faktor, vor allem wenn es um den Aufbau von modernen Rechenzentren geht, bei denen Flash-Speicher in die Storage-Architektur eingebunden wird.
Flash-Speicher erhöht das IOPS-Potenzial enorm und reduziert die Latency auf der Ebene des Speichermediums. Doch es kann dann zu anderen Verzögerungszeiten – an einer anderen Stelle im Storage Stack – kommen. So kann es durchaus der Fall sein dass diese Stellen die Gesamtperformance des Speicher-Subsystems so massiv bestimmen, dass der Einsatz von „Flash Only“ nicht das gewünschte Resultat bringt.
Der Storage Stack
In einer typischen Speicherarchitektur spielen verschiedene Ebenen zusammen. Zu unterst liegt das (oder die) Speichermedien, auf denen die Anwender die Daten ablegen (Speichern) und Zugriff auf die Daten bekommen (Lesen). Die zweite Komponente, die Storage Software, kontrolliert, wie die Daten auf das Speichermedium geschrieben werden, und bietet zudem weiterreichend Speicherfunktionen an. Dazu gehören zum Beispiel Funktionen wie Datenschutz (RAID-Konzepte), Snapshots oder die Replikation der Daten. Diese Ebene zeichnet für die Verteilung und die zeitliche Anordnung des Ein-/Ausgabeverkehrs auf das Speichermedium verantwortlich.
Die dritte Instanz ist die „Compute-Einheit“ (also die Prozessoren), auf der die Speichersoftware läuft. Und zu guter Letzt kommt vor allem in traditionellen Storage-Architekturen noch das Speichernetzwerk dazu. Über diese Kommunikationsschiene werden die Daten hin zur Applikationsebene und von ihr wieder zurück in das Storage-Subsystem übertragen.
Die IOPS spiegeln vor allem die Performance der unteren Ebene, des Speichermediums, wider. Der Bandbreiten-Parameter bezieht sich in erster Linie auf das Speichernetzwerk und das Speichermedium. Die Latency dagegen sagt aus, wie lange der komplette Zyklus dauert, also von der Eingabe an der Applikation bis zur endgültigen Ausgabe durch die Applikation. Damit bezieht sich nur die Latency auf alle vier Schichten – und damit auch auf die Effektivität der Speicher-Software sowie die Fähigkeit dieser Komponente, die verfügbaren Compute-Ressourcen für die Verarbeitung der Ein-/Ausgabeoperation heranzuziehen.
Den Lese- und Schreibvorgang kann man in zwei Teile aufsplitten: Einmal die Zeitspanne, die für das Platzieren oder „Entnehmen“ der Daten auf dem Medium anfällt und einmal die Zeit, die die Daten benötigen, um das Speichersubsystem selbst zu durchlaufen. Kommt ein Festplatten-basiertes Storage Array zum Einsatz, dann ist die Zeitspanne für das Rotieren des Harddisk-Mediums um eine Größenordnung höher als die Zeit, die für das Durchlaufen der Daten im übrigen Storage-Subsystem anfällt.
Das führt zu einem gängigen Ansatz: Aufgrund der Preisentwicklung bei Solid State Disks (SSDs) schwenken viele IT-Verantwortliche bei ihren Speichersystemen um und setzen Flash-Speicher ein. Dabei werden die aktiven Daten – also die Informationen, die immer wieder gebraucht werden – nun auf dem Flash-Medium abgelegt. Damit ändern sich die nötigen Zeitspannen: Fielen bei den Festplatten noch Schreib/Lesezeiten in Millisekundenbereich an, so sind es beim Flash-Speicher nur mehr Mikrosekunden. Doch damit werden erstmals die Verzögerungszeiten sichtbar, die im restlichen Storage Stack anfallen. Daher müssen nun auch diese bislang „unsichtbaren“ Verzögerungszeiten ins Visier genommen werden, wenn man eine optimale Performance zu vernünftigen Kosten im Speicherbereich anstrebt.
Übliche Ansätze, um die Auswirkung der Schreibverzögerungen auf rotierenden Medien zu verringern, war zum einen das Erhöhen der Rotationsgeschwindigkeit. Doch hier ist die technologische Grenze bei 15.000 Umdrehungen pro Minute stehen geblieben. Seagate hatte bereits 2002 mit der Cheetah-Familie diese Umdrehungsgeschwindigkeiten spezifiziert. Höhere Rotationsgeschwindigkeiten finden heutzutage keine Anwendung. Deswegen wurden die Daten auf mehrere (dutzende oder gar hunderte) von Festplatten parallel verteilt. Diese einzelnen „Stripes“ werden dann als ein Volume für die Anwendung bereitgestellt. Das ergibt eine Verbesserung, doch nach wie vor war das Speichermedium selbst der Flaschenhals.
Eine weitere Quelle, die einen negativen Einfluss auf die Latency hat, ist das Speichernetzwerk. Üblicherweise kommt an dieser Stelle der Fibre Channel (sehr gängig ist eine Bandbreite von 4 GBit/s, heute auch mit bis zu 16 GBit/s) zum Einsatz. Aber auch Ethernet (mit mindestens 1 GBit/s Bandbreite) ist im Speicherbereich zu einer gängigen Übertragungstechnologie geworden. Mittlerweile sind auch 10 GBit/s im Serverbereich häufig anzutreffen, neuere Specs versprechen schon 40 und sogar 100 GBit/s. Aber auch hier muss man relativieren: Der Einfluss durch das Speichernetzwerk war bei den rotierenden Medien – Festplatten – keine ausschlaggebende Größe.
All Flash-Konzepte und die Latency
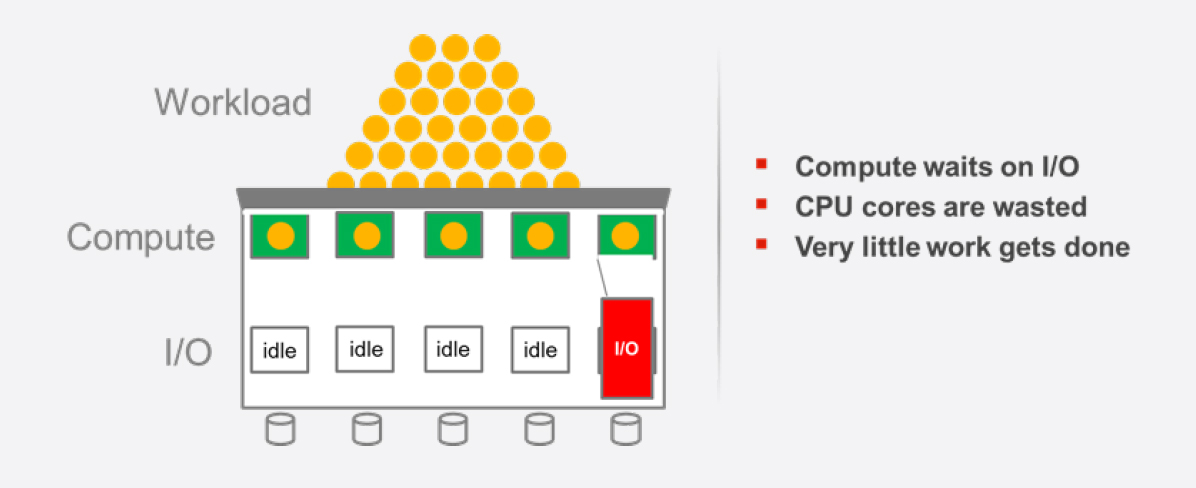
Wenn nun IT-Verantwortliche den Umstieg auf Flash-Speichermedien angehen, ergibt sich eine spürbare Verbesserung. Denn die Flash-basierten Medien reagieren vergleichsweise sofort. Deswegen denken viele IT-Verantwortliche, dass der Umstieg auf All-Flash Arrays ihr Latency-Problem löst. Und das stimmt auch, wenn man den Blickwinkel „pro Laufwerk“ wählt. Doch mit dem Einsatz der Flash-Technologie verschiebt sich das Latency-Problem. Es zeigt sich nicht mehr beim Speichermedium, sondern der Speicher-Controller (üblicherweise im Array) gerät in den Fokus. Denn er ist für das Platzieren der Daten auf dem Speichermedium bzw. das Auslesen vom Medium zuständig.
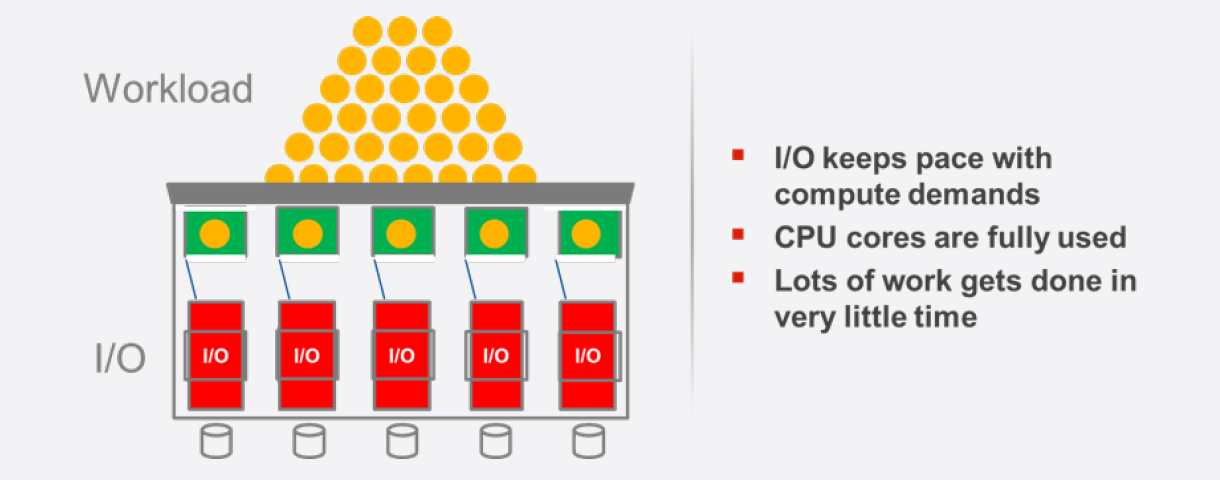
In Zeiten der Festplatten-Arrays reicht es normalerweise aus, wenn der Speicher-Controller eine CPU mit nur einem Prozessorkern war. Denn eine derartige CPU besaß genügend Rechenleistung, um alle Ein-/Ausgabeanforderungen abzuarbeiten. Denn die meiste Zeit musste ja auf die Festplatten gewartet werden. Doch mittlerweile werden beim Flash-Speicher die I/O-Requests sofort erfüllt. Eine Gruppe von Flash-Laufwerken in einem Storage System kann weitaus mehr Informationen wegschreiben, als eine Einkern-CPU liefert. Doch heutzutage haben gängige Prozessoren eine Vielzahl von Kernen, so dass genügend Rechenpower zur Verfügung steht. So ist ein Storage Controller in der Lage, mit den steigenden Möglichkeiten der Flash-Speicher Schritt zu halten.
Das Problem zeigt sich nun allerdings im Bereich der Speicher-Software, die auf dem Speicher-Controller zum Einsatz kommt. Denn sie ist vielfach nicht dazu in der Lage, Parallelverarbeitung, wie sie bei Prozessoren mit vielen Kernen möglich ist, auszunutzen. Wenn die Storage-Software „singlethreaded“ ausgelegt ist, braucht sie einen Prozessor mit höherer Taktfrequenz (die entsprechend teurer sind), um schneller ablaufen zu können. Vorteile aufgrund der Multiprozessor- und Multicore-Architektur einer CPU wirken sich kaum aus. Daraus ergibt sich in eine All-Flash-Architektur oftmals der Zustand, dass die Speichermedien auf die Lieferung von Daten warten und die vielen Prozessorkerne eines Storage Controllers ebenfalls nichts zu tun haben – alles nur, weil die Speicher-Software nicht die Vorteile der Parallelverarbeitung realisieren kann.
Im Bereich der Speichernetzwerke kommen Netzwerktechnologien wie Fibre Channel (mit bis zu 16 GBit/s) und Ethernet mit 10, 40 und künftig sogar 100 GBit/s in den bezahlbaren Bereich. Damit sind moderne Rechenzentren auch in Bezug auf die Speichernetzwerke in der Lage, die Daten schneller zu übertragen.
Lösungsmöglichkeiten
Um nun die Storage Software für die neuen Umgebungsparameter zu rüsten, muss ein Umdenken statfi8nden. Heutige Softwarelösungen für diesen Bereich fokussieren sich auf das Bereitstellen von Funktionalitäten, die dem Administrator das Leben vereinfache. Dazu gehört die einfache Verwaltung von LUNs oder Volumes, das Anfertigen von Snapshots, das Replizieren der Daten. Die Deduplizierung und die Kompression oder auch das Verschlüsseln der Informationen. Dagegen bleiben die Aspekte eher unberücksichtigt, die ein Administrator nicht sieht, wie etwa das Verteilen der I/O-Requests und das Ausnutzen der Multikern-Architektur moderner Prozessoren. In diesem Umfeld hat der Datacore Parallel Server erstmals die 5-Millionen-IOPS-Schallmauer durchbrochen und setzt sich mit weitem Abstand an die Spitze der Top Ten der SPC-1-Performance-Liste. Der erzielte Wert bedeutet mehr I/O-Operationen pro Sekunde als die beiden bisher Führenden – Huawei Oceanstor 18800 V3 und Hitachi VSP G1000 – zusammen.

Mit der Vorlage des vierten SPC-1-Benchmark komplettiert Datacore eine beeindruckende Serie von Rekordmarken in sämtlichen praxisrelevanten SPC-1-Kategorien, darunter die Gesamtdurchsatzleistung SPC-1 IOPS, die durchschnittliche Antwortzeit bei Vollauslastung sowie das Preis-Performance-Verhältnis nach SPC-1. In den kontrollierten und dokumentierten Testverfahren wurden dem SPC-1-Gremium Single-Node-Systeme ebenso wie hochverfügbare Zweiknoten-Konfigurationen zur Prüfung vorgelegt.
Das neue Rekordergebnis wurde in einer hyperkonvergenten Konfiguration auf zwei Standard-Lenovo-Servern erzielt, die über Fibre Channel mit 12 externen Hosts verbunden waren, die den notwendigen I/O-Verkehr über anspruchsvolle Unternehmens-Applikationen generierten. Diese Zweiknoten-Konfiguration arbeitete mit dem Datacore Parallel Server, einer Softwarelösung, die das moderne Multicore-Computing nutzt, um I/O-Prozesse parallel zu verarbeiten, damit also Standard-Rechner in hochperformante Server verwandelt. Diese sind bestens gerüstet für anspruchsvolle Anwendungen mit besonderen Anforderungen an die I/O-Leistung sowohl im Speicher-Netzwerk als auch bei hyperkonvergenten Einzelsystemen.
„Der neue Rekord stellt einen wichtigen Schritt dar, aber eigentlich ist er für Datacore nur der Ausgangspunkt dafür, was mit Parallel I/O- und Multicore-Technologie möglich ist”, sagt George Teixeira, CEO von Datacore Software. Denn die Ergebnisse wurden auf zwei kleinen Standardservern erzielt. Die Flexibilität der Software erlaube es, dass weitere Kerne und mehr Server-Knoten dazu gekoppelt werden. Die Leistung ist umso beeindruckender, als sie auf einem externen System erzielt wurde, das über ein Fibre Channel-SAN (Storage Area Network) angebunden war, wo andere Produkte erheblich höhere Latenzzeiten aufwiesen. Mit seinen Partnern Qlogic, Brocade und Lenovo konnte Datacore eine Konfiguration präsentieren, die unter Beweis stellte, dass moderne Fibre Channel-SANs kein Hindernis für extrem schnelle Storage-Performance darstellen müssen.
Die Zahlen belegen eindrücklich, dass der Datacore Parallel Server eine revolutionäre Softwarearchitektur für I/O-intensive und Latenz-sensitive Applikationen darstellt. Die Technologie verwandelt Standardrechner in leistungsstarke Parallel-Storage-Server. Dabei wird eine Vielzahl von unabhängigen I/O-Streams simultan über mehrere CPU-Kerne ausgeführt, was die Abarbeitungszeit dramatisch verkürzt. So werden die von der seriellen Verarbeitung gesetzten Grenzen und Engpässe beseitigt und die Server können weit mehr Arbeiten durchführen und dabei I/O-intensive Anwendungen signifikant beschleunigen. (rhh)
Quellenangaben:
SPC-1 Full Disclosure (FDR) Report: Die streng überwachten Tests nach SPC-1 prüfen die Systemperformance für kritische Anwendungen auf Unternehmensebene, wie sie für Datenbanken und Transaktionssysteme typisch sind. Die Konfiguration mit Datacore Parallel Server und zwei Lenovo System x3650 M5-Systemen kann im kompletten SPC-1-Report im Detail eingesehen werden.
Das Storage Performance Counsil (SPC) ist ein herstellerunabhängiges Gremium für Standards, das sich auf die Storage-Industrie fokussiert. Das SPC schuf den ersten standardisierten Performance-Benchmark, der auf die Bedürfnisse der Storage-Industrie ausgerichtet war. Von der Evaluation auf der Komponenten-Ebene bis zur Messung kompletter verteilter Storage-Systeme bietet das SPC-Benchmark-Portfolio unabhängig geprüfte, gründliche und zuverlässige Messungen von Performance, Preis-Leistung und Stromverbrauch. Hier gibt es mehr Informationen über SPC und die Benchmarks.


