Moderne Storage-Konzepte für Compute Cluster
15. Dezember 2013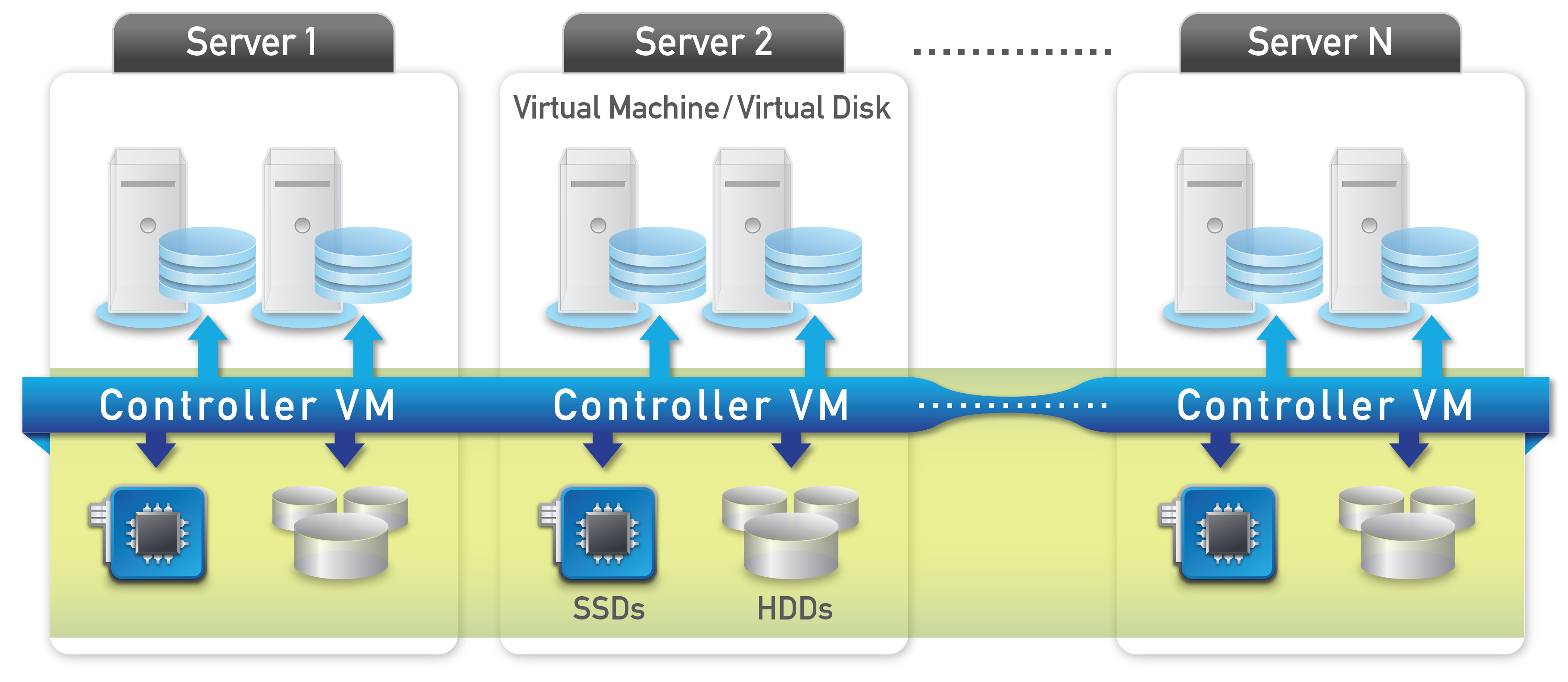
Traditionelle Konzepte a la Network Attached Storage (NAS) und SAN (Storage Area Networks) reichen für die heutigen Anforderungen bei Virtualisierungsplattformen nicht mehr aus. Moderne Scale-out-Cluster greifen effizient auf Storage zu, der mit Hilfe des Filesystems in den geclusterten Servern verwaltet wird. Der „Nutanix Complete Cluster“ gilt in diesem Zusammenhang als eine ausgereifte Architektur für virtualisierte Storage-Umgebungen.
In virtualisierten Umgebungen zieht die Verwaltung von virtuellen Maschinen (Virtual Machines, VMs), die sich in Sekundenschelle erzeugen und verschieben lassen, einen hohen Aufwand nach sich, wenn der Storage über ein Speichernetzwerk (SAN oder NAS) verwaltet wird. Daher sind Google und andere Mega-Rechenzentrumsbetreiber dazu übergegangen, ein proprietäres Filesystem anstelle eines Speichernetzwerks zu nutzen. Dieses verwaltet Server und Storage in einer Scale-out-Architektur wie einen Cluster. Die nötigen Speicherfunktionen, wie Failover, Backup, Snapshots und Disaster Recovery, sind ebenso möglich wie im NAS.
Auf eine entsprechende, nicht-proprietäre Filesystem-Lösung für Storage und Server musste man bislang warten. Doch der amerikanische Hersteller Nutanix hat dieses Potenzial erkannt und bietet für Commodity-Server eine Lösung: Es werden SSD- (Solid State Disks) und HDD-basierte (Hard Disk Drives) Storage-Kapazitäten als Appliances bereitgestellt mit Hilfe des Betriebssystems „Nutanix OS“ verwaltet. Dabei werden die Hypervisoren von VMware (vSphere) und Microsoft (Hyper-V) unterstützt.
Vom Prinzip her wird lokaler Speicher einzelner Rechenknoten vom „Scale-Out Converged Storage“ (SOCS) virtualisiert und als Pool verwaltet. SOCS ist mit der Compute-Schicht des Servers integriert, auf der die VMs basieren. Daher kann SOCS die VMs und den Speicher sehr effizient verwalten. Wenn hoher I/O-Bedarf von einer bestimmten VM kommt, erhält sie den entsprechenden Storage, der für eben diese hohe Leistung optimiert ist – in der Regel auf der Basis von SSDs. Die Skalierbarkeit reicht von wenigen Cluster-Nodes bis zu einer hohen Anzahl. Sollten SSDs oder Nodes ausfallen, fangen Hochverfügbarkeitsmechanismen dies auf.Zwischen jedem Laufwerk (SSD oder HDD) und den darauf abgelegten VMs beziehungsweise den virtuellen Festplatten (Virtual Disks) sitzt eine Controller-VM, die den Datenaustausch steuert sowie Verwaltungsfunktionen erfüllt. Die Gesamtheit der Controller-VMs bildet ein untereinander kommunizierendes, verteiltes System, das integraler Bestandteil von SOCS ist. Die Anzahl der Controller-VMs ist ebenso unbegrenzt wie die Zahl der Nodes.
Optimierung der Kapazität
Alle SSDs in den Nodes stellen Speicherplatz für einen leistungsfähigen Cache bereit, der genutzt wird, wenn Gast-VMs Daten schreiben. Mit diesem „Heat-Optimized Tiering Cache“ (HOTcache) können aktuellste und häufig benutzte ("heiße") Daten in den SSDs abgelegt werden, ältere ("kalte") Daten mit weniger häufigen Zugriffen hingegen auf günstigen, aber langsameren SATA-Festplatten, die nicht so schnell wie die relativ teuren Enterprise-SSDs sind. Auf diese Weise ist dafür gesorgt, dass Daten aus VMs immer mit der höchsten Leistung verarbeitet werden. Durch das Bereithalten von Kopien sorgt HOTcache für Fehlertoleranz.
Die in Nutanix OS 3.5 (August 2013) verfügbar gewordene „Elastic Deduplication Engine“ dedupliziert Daten im Arbeitsspeicher, auf SSDs und auf Festplatten. Da die Deduplizierung in Echtzeit anhand Lese-I/O-Zugriffsmustern angepasst wird, lässt sich nicht nur der verfügbare Speicherplatz maximieren, sondern auch die Ausführungsgeschwindigkeit der jeweils gerade am meisten beanspruchten Anwendung. Für Anwendungen mit einem großen Ressourcenverbrauch wie etwa Virtual Desktop Infrastructure (VDI)-Implementierungen kann die Technik die verfügbaren Flash- und Arbeitsspeicherressourcen um das bis zu Zehnfache erhöhen, wodurch annähernd verzögerungsfreie Antwortzeiten bei den Applikationen erreicht werden sollen. Noch in diesem Jahr soll mit dieser Technik auch das Speichern von „kalten Daten“ auf Festplatten optimierbar werden.
Der verteilte Data Maintenance Service "Curator" ist ein auf „Map Reduce“ basierendes Framework, das die massiv parallelen Datenverwaltungsoperationen im Hintergrund steuert. Zu diesen Tätigkeiten gehört die Migration "kalter" Daten auf niedrigere Prioritätsebenen, die Entsorgung gelöschter Daten, die Aufrechterhaltung der Datenkonsistenz, die Datenreplikation zwecks Fehlertoleranz, die Neu-Allokierung von Daten, wenn ein Laufwerk hinzugefügt oder entfernt wird, und schließlich die Migration von Daten, wenn eine VM von einem Node zu einem anderen Node bewegt wird, um so den lokalen Datenzugang der VM zu erleichtern.
Flashstore und Diskstore
Daten werden zuerst in den Speicher-Pool des SSD-basierten Flashstore geschrieben, bevor sie nach angemessener oder vorgegebener Zeit als "kalte" Daten an den Diskstore-Pool aus SATA-Festplatten migriert werden. Auch der umgekehrte Fall lässt sich realisieren. Für virtuelle Festülatten (Virtual Disks, vDisks), die VMs niedriger Priorität unterstützen, lässt sich Flashstore überspringen. Der über den ganzen Cluster verteilte Diskstore hält große Speicherkapazitäten für "kalte" Daten bereit.
Damit sowohl die Leistung hoch als auch die Kosten für die Speichermedien niedrig gehalten werden, sorgt Heat-Optimized Tiering für die optimale Verteilung der Daten. Administratoren können neue VMs schnell und einfach mit der Quickclone-Funktion in Betrieb nehmen. Bei einem Quickclone handelt es sich um einen beschreibbaren Snapshot, der sich wie eine vDisk verhält. Der Systembetreuer kann sie einer VM zuweisen, Daten darauf schreiben und wiederum Snapshots davon anfertigen, etwa für virtuelle Desktops oder für Backup-Zwecke (im Nur-Lesen-Modus).
Der nötige Speicherbereich wird den jeweiligen VMs per „Thin Provisioning“ zugewiesen. Der Admin ist in der Lage, jeder virtuellen Festplatte den erforderlichen physischen Speicher zuzuordnen. Er kann auch minimalen Reserveplatz vorgeben, um so einer Sammlung von virtuellen Festplatten ein bestimmtes Speichervolumen zu garantieren. Die Funktion "Converged Backup" stellt solchen vDisks auch Backup- und Recovery-Fähigkeiten bereit. Je nach verfügbarem Speicherplatz lassen sich so pro Appliance mehrere Monate an Sicherheitskopien unterbringen. Auf einen Klick hin lässt sich die Backup-Kopie einer vDisk wiederherstellen.
In Nutanix OS 3.5 wurde zudem ein natives Disaster Recovery hinzugefügt, um die Kapazitäten zu optimieren. Außerdem steht dem Admin nun der Storage Replication Adapter (SRA) für den VMware Site Recovery Manager (SRM) zur Verfügung. Mit Hilfe des SRA können Kunden ihre bestehenden Investitionen in VMware SRM nutzen, um Nutanix-VM-spezifische Disaster-Recovery-Regeln zu verwalten. Der SRM ist eines von mehreren VDAP-kompatiblen Fremdanbieterwerkzeugen (VDAP: VMware vStorage API for Data Protection), die Nutanix für das Offsite-Backup und -Disaster-Recovery unterstützt.
Hochverfügbarkeit
Zusätzlich zur Skalierbarkeit und Fehlertoleranz unterstützt der Nutanix Complete Cluster Hochverfügbarkeit, indem er Cluster RAID bereitstellt. Mit dieser Funktion werden Daten über Disks in einem Node hinweg "gestriped" und über den ganzen Cluster hinweg repliziert. Sollten Disks oder gar komplette Nodes ausfallen, stehen die Daten bzw. VMs immer noch bereit.
Die Metadaten zur Verwaltung der Cluster-Daten befinden sich nicht, wie üblich, in den Laufwerkscontrollern, sondern in Medusa, dem verteilten Metadaten-Service von Nutanix. Dieser sorgt für Skalierbarkeit, wenn der Cluster wächst, und repliziert die Daten auf mehreren Nodes zwecks Fehlertoleranz. Auch dieser Service ist hochverfügbar.
Moderne Hypervisoren können eine genutzte "Live-VM" während des Betriebs verschieben. Die Nutzung war bislang NAS-Installationen vorbehalten, was Organisationen zur NAS-Nutzung zwang. Nun unterstützt auch Complete Cluster dieses Leistungsmerkmal. Auch vDisks auf der Appliance sind logische Einheiten, die mit Nutanix Instant vDisk Motion vollständig mobil gehandhabt werden können. Die Betriebssystemversion 3.5 stellt den Administratoren "Nutanix Prism" zur Verfügung, ein Management-Framework einschließlich einer überarbeiteten Oberfläche, welche die Bedienung vereinfacht.
Prism ordnet und zeigt alle Informationen zu Systemen und VMs leicht verständlich an, damit sie unmittelbar für weitere Aktionen verwendet werden können. Der gesamte Server-, Storage- und Netzwerkbetrieb wird in nur einer Maske dargestellt. Zudem sollen eingebaute Analysefunktionen die Korrelation von Ereignissen ermöglichen und die Fehlersuche und -beseitigung vereinfachen. Da sie mit HTML 5 entwickelt wurde, kann die Benutzeroberfläche praktisch jedes Endgerät nutzen.
Außerdem beinhaltet das neue Framework eine REST-basierende API, so dass sich Nutanix auf einfache Art und Weise in Enterprise- oder Cloud-Managementsysteme integrieren lässt. Darüber hinaus enthält die API einen funktionsreichen Explorer für das einfache und diskrete Sampling individueller API-Befehle und erlaubt Zugriff auf sämtliche Berichts- und Managementfunktionen in einem Managementsystem für Cloud-Orchestrierung wie etwa Openstack und VMware vCloud Automation Center.


