Kubernetes-Daten vor Cyber-Attacken und Verlust schützen
26. November 2021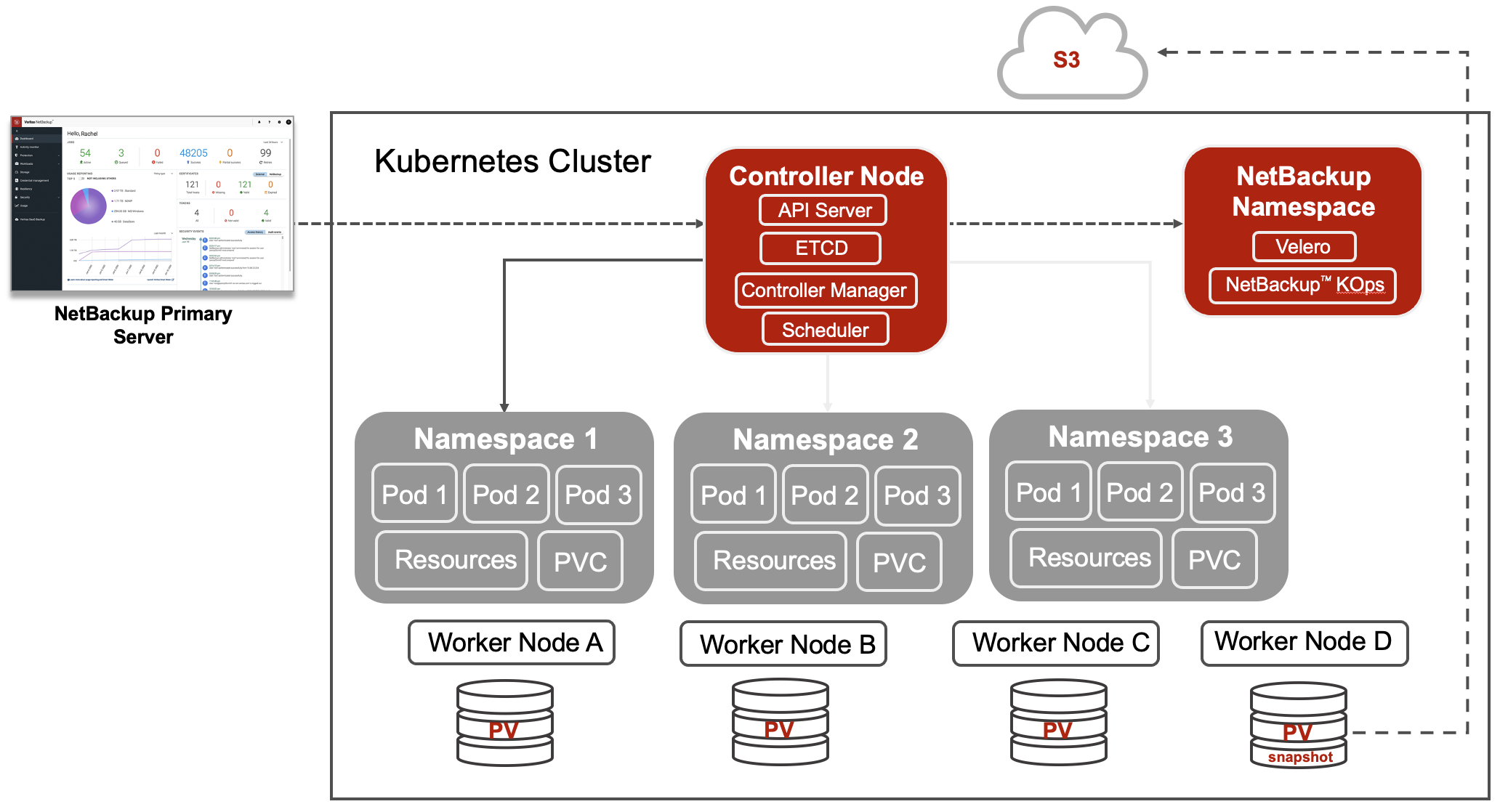
Auch Kubernetes ist inzwischen im Visier von Ransomware. Als eine der ersten operierte die Malware Siloscape aus einem Container heraus und nutzte schwach konfigurierte Sicherheitsfunktionen in Kubernetes-Clustern aus. Der Schadcode kann auf Cluster-Ebene Anmeldeinformationen und andere geschäftskritische Daten stehlen.
Das Open-Source-System rund um Kubernetes ist für viele Anwender Neuland, weshalb schwache Konfigurationen wahrscheinlicher sind, wie eine Forschungsstudie von Stackrox aus dem Jahr 2020 zeigt. Darin gaben 67 Prozent der Befragten schwerwiegende Fehlkonfigurationen in ihrer Kubernetes-Umgebung zu.
Die folgenden Tipps helfen Unternehmen dabei, Daten auf Kubernetes gegen Angriffe, Malware und menschliche Fehler widerstandsfähiger zu machen:
Den Grundprinzipien für Sicherheit folgen
Kubernetes liefert eine der besten und verständlichsten Dokumentationen, um die Plattform selbst sicher aufzusetzen. Die Benutzer und ihre Accounts sollten mit guten, starken und unterschiedlichen Passwörtern gesichert und ihre Zugriffsprivilegien auf ihre Aufgaben entsprechend zugeschnitten sein. Es ist empfehlenswert, dass kritische Daten auf ihrem Weg zwischen Containern und Pods verschlüsselt sind.
Die Dokumentation der Linux Foundation erklärt anschaulich Details zur richtigen Konfiguration, Verwaltung und Sicherung der Cluster. Parallel arbeitet die Community daran, Software-Fehler zu finden und zu schließen. Patches helfen dabei, Hintertüren in der Architektur zu schließen.
Daten vor Fehlern schützen
Der Faktor Mensch wird dadurch nicht allerdings ausgeschlossen. Wer die Daten in einer Kubernetes-Umgebung selbst sichern und die Folgen menschlicher Fehler eindämmen will, sollte die Files per Backup sichern. Die Struktur und Architektur verlangt nach einem speziellen Ansatz, um die großen Vorteile von Kubernetes nicht zu verspielen.
Kubernetes-Plattformen basieren auf einer Hierarchie aus mehreren Worker-Nodes und dem Cluster-Master-Node an der Spitze. Master und Worker-Nodes kommunizieren über definierte Prozesse, die in jeder Distribution enthalten sind. Darüber lassen sich Namespaces und Pods beziehungsweise Container automatisch einrichten und auf die jeweiligen Worker-Nodes ausrollen sowie überwachen. Um Datenbanken einbinden zu können, werden die Namespaces mit Persistent Storage Volumes, also festem Speicherplatz, verknüpft.
Nach dieser Struktur sollten die Elemente per Backup gesichert werden. Dank Container-Architektur lassen sich persistente und nicht-persistente Daten voneinander trennen und je nach Applikation optimal nutzen. Auch Updates können schnell eingespielt werden. Wichtig ist, dass das Backup die häufigst genutzten Distributionen auf dem Markt vollständig unterstützt. Den größten Kubernetes-Marktanteil hat hierzulande Red Hat Openshift. Aber auch VMware drängt mit Tanzu immer stärker in den Markt.
Namespaces umfassend sichern
Kubernetes operiert mit sogenannten Namespaces. Diese sind meist als Projekte oder Applikationen definiert, die durch Pods, Container, Konfigurationsinformationen und den zugehörigen Storages den eigentlichen Business Value einer Kubernetes-Umgebung liefern.
Die Backup-Plattform sollte über eine Namespace-Schnittstelle in das Cluster integriert werden und das Discovery des Clusters selbstständig durchführen und dort manuelle und geplante Backup-Abläufe sowie das Wiederherstellen der Daten abwickeln.
Damit die Applikationen ganzheitlich geschützt und die Skalierung und Portierbarkeit der Kubernetes-Umgebung gewahrt bleiben, sollte ein Namespace mit allen Komponenten gesichert werden. Gleichzeitig muss es im Recovery-Fall möglich sein, die Persistent Volumes unabhängig vom Namespace wiederherzustellen, da auf ihren Datenlayern logische Fehler auftreten können. Um die Agilität von Kubernetes zu wahren, sollte die Backup-Lösung zudem das Wiederherstellen von Namespaces auf alternativen Clustern unterstützen.
Zugriffsrechte klar definieren
Wenn die Kommunikation zwischen Backup-Software und Kubernetes-Master nach abgestimmten Zertifikaten und Credentials abläuft, lassen sich essenzielle Informationen für Betrieb und Sicherheit gewinnen. Für die gegenseitige Authentifizierung des Kubernetes-Clusters und des Backup-Systems gibt es Tokens und CA-Zertifikate, mit denen sich der Datenaustausch sicher verschlüsseln lässt.
Die Zugriffsrechte für die Datensicherung und -wiederherstellung sollten nur für Ressourcen der Kubernetes-Umgebung gelten, die der jeweilige User verwalten oder nutzen darf. Das bedeutet, dass ein Backup-Anwender nur die Namespaces und Persistent Storage Volumes des Clusters sehen kann, für das er eine Berechtigung hat. Auf diese Weise lassen sich Dev-, Test- und Produktionsverantwortlichkeiten separieren. Auch bei der Konfiguration empfiehlt es sich, Zugriffsrechte zu definieren, die im Backup-System über einen Rolebased Access umgesetzt werden. Dieser Ansatz stärkt die Widerstandsfähigkeit gegen Cyberattacken.
DevOps- und Backup-Teams mit Automatisierung entlasten
Eine Backup-Lösung sollte zudem automatisch und regelmäßig untersuchen, ob in den Clustern neue Namespaces angelegt wurden. Daher müssen Kubernetes-Distribution und Backup-Lösung einwandfrei zusammenspielen. Sinnvoll ist auch der Ansatz, logische Selektionen mit der Zuordnung der entsprechenden Backup-Pläne automatisch und intelligent neuen Namespaces zuzuweisen. Das reduziert in wachsenden Kubernetes-Farmen das Risiko, dass ein Projekt oder eine Applikation nicht ordnungsgemäß gesichert wird.
Zudem entlasten Automatismen die IT-Teams bei Discovery und Konfiguration und senken das Risiko von Datenverlusten für DevOps-Teams. Diese können ihre Datenbestände mit dem entsprechenden Rechtekonzept auch selbst wiederherstellen. Das verkürzt die Entwicklungszeiten und entlastet die Back-up-Verantwortlichen. Auch bislang erfolglose Backup-Prozesse lassen sich durch die Integration aus Distribution und Backup-Konzept zeitgesteuert neu starten. Die Verantwortlichen werden dann über einen Event-Alarm in der entsprechenden GUI informiert.
Auf Integrationsmöglichkeiten achten
Ein Backup-System sollte mit etablierten Standards wie Velero interagieren, aber auch intelligente Erweiterungen unterstützen. So kann die Anbindung an ein durch das Backup gesteuerte Retention-Management mit Replikationsmöglichkeit helfen, sich vor Ransomware zu schützen. Wichtig ist dabei, die 3-2-1 Regel zu berücksichtigen. Eine sinnvolle konzeptionelle Ergänzung ist auch der Backup Data Mover. Damit lassen sich die Backup-Storage-Ziele auf die vom Anbieter unterstützte Kompatibilität erweitern. Kubernetes ist dann Ende-zu-Ende in ein zentrales Backup- und Recovery-Konzept eingebunden, was den Betrieb von einzelnem Best-Of-Bread Backup-Systemen je Workload vermeidet. Dadurch lassen sich Kosten reduzieren, die Komplexität eindämmen und Risiken verringern.
Ein funktionierendes Backup ist auch für Kubernetes-Anwender das stärkste Mittel gegen Ransomware-Erpressungsversuche und Datenverluste durch menschliche Fehler. Die Plattform NetBackup von Veritas ermöglicht eine hochgradige Automatisierung und die Integration in Legacy-Systeme und virtuelle Umgebungen für die meisten Workloads auf dem Markt – onsite sowie in der Cloud. Das senkt den Aufwand und die Kosten von Sicherungen. Zudem fällt kein kritisches System und keine wichtige Datei durch das Backup-Raster. Wenn Ransomware oder menschliche Fehler wichtige Daten korrumpieren, können Kubernetes-Anwender sie zuverlässig wiederherstellen. (rhh)


