Hyper-V: Performanceprobleme bei VMs beheben
8. Januar 2014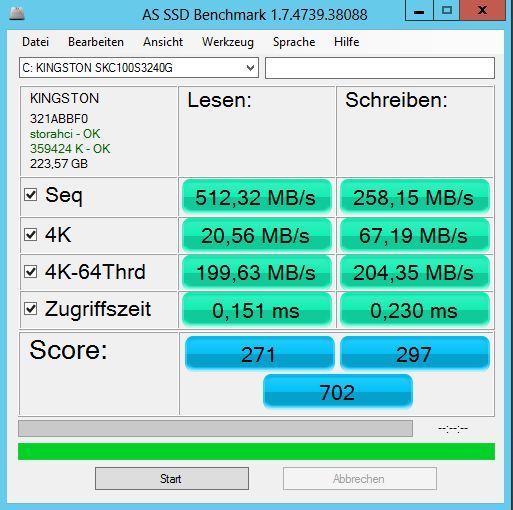
Nur objektive Messwerte geben dem Administrator die Basis, um Performanceprobleme bei Virtuellen Maschinen beim Hyper-V zu diagnostizieren. Durch die direkte Gegenüberstellung der gesammelten Daten kann eine sinnvolle Darstellung gewährleistet werden. So erhält der Systembetreuer einen Überblick der aktuellen Situation und kann bei Problemen passend eingreifen.
Ein häufig auftretendes Problem im Bereich der Virtualisierungstechniken stellt die geringe Gesamtperformance der Virtuellen Maschinen (VMs) dar. Administratoren müssen sich im Alltag oftmals mit diesen, teilweise schwer zu diagnostizierenden Problemen beschäftigen: entweder weil die Anwender über zu geringe Rechnergeschwindigkeit und zu hohe Leerlauf- beziehungsweise Wartezeiten klagen, oder wenn die Gesamtperformance einzelner oder mehrerer Serverinstanzen zu Wünschen übrig lässt. Daher werden wir im folgenden Beitrag auf die Diagnose dieser Situationen eingehen und passende Problemlösungen entwickeln.
Rechengeschwindigkeit als subjektive Einschätzung
Bei Aussagen bezüglich der Rechnerperformance stellt sich für den Systembetreuer immer die Frage, ob es sich bei den vermeintlich langsamen Maschinen nur um ein Problem mit der subjektiven Wahrnehmung des Anwenders handelt. Denn die Aussage: „Das System ist langsam!“ hat für verschiedene Personen ganz unterschiedliche Bedeutungen. Die Performance ist langsam, ja aber im Vergleich zu was? Ist die günstige Büromaschine mit der VM für die Buchhaltung langsam im Vergleich zur High-End CAD-Workstation mit SSD-Verbund des Kollegen oder langsam im Vergleich zum alten Windows XP Rechner mit 1 GByte RAM den die Dame oder der Herr aus der Buchhaltung (als inzwischen eingemottetes Vorgängermodell) unter dem Schreibtisch stehen hatte? Ist die Verhältnismäßigkeit der angestellten Geschwindigkeitsvergleiche gegeben?
Daher sollte der Administrator hier auf vernünftige Vergleichswerte setzten und neben einem subjektiven Eindruck der Performanceprobleme auch noch Erfahrungswerte mit ähnlichen Modellen und Systemen anbringen. Ansonsten dürfte eine Fehlersuche sich als schwierig bis unmöglich herausstellen.
Wie groß ist das Umfeld der Performanceprobleme?
Anstatt sich nun gleich auf die spezifischen Einzel- oder Eigenheiten der Geschwindigkeitsprobleme zu konzentrieren, treten erfahrene Administratoren erst einmal einen Schritt zurück und betrachten das gesamte Umfeld der gemeldeten Performanceeinbrüche. Treten diese isoliert auf, oder häufen sich die Anfragen der genervten Anwender und Administratoren, deren VMs sich auf demselben Hostsystem befinden?
Oftmals liegt die Lösung so nah, und der Administrator verschiebt ein paar VMs des betroffenen Hostsystems auf einen anderen Server, und die nun gleichmäßiger verteilte Auslastung der Server bringt den erhofften Geschwindigkeitsschub. Dies kann beispielsweise auftreten falls sich die VMs zwar zahlenmäßig gleich auf die jeweiligen Hostserver verteilen, aber unterschiedliche Ressourcen- anfragen oder die jeweilige Auslastung sich ungewollt aufschaukeln.

Vergleichswerte schaffen
Sollte sich das Problem nicht so einfach gestalten, stehen die Administratoren nun doch an dem Punkt, eine genaue Analyse erstellen zu müssen. Hier ist zunächst das Schaffen entsprechend objektiver Vergleichswerte wichtig. Somit muss der Administrator in seinen Werkzeugkasten greifen und mit verschiedenen Benchmarks die Performance in den betroffenen virtuellen Instanzen messen, sowie – vergleichsweise – auch noch in VMs bei denen keine Performanceprobleme auftauchen.
So können die jeweiligen Messwerte gegenübergestellt werden. Eventuell verbirgt sich hier bereits die passende Lösung. Das Interpretieren der Messwerte bei VMs benötigt doch etwas mehr an Grundwissen als beim direkten Vergleich von physikalischen Systemen.
Eine Sache die Administratoren ganz klar vor Augen haben sollten ist, dass gemessene Performanceauslastungen nur die Auslastung der zugewiesenen Ressourcen wiederspiegeln. Sollte der VM beispielsweise von insgesamt vier verfügbaren CPU-Kernen des Hostsystems ein Kern zugewiesen worden sein, und das Ergebnis der CPU-Messung in der virtuellen Maschine zeigt eine Auslastung von 100 Prozent an, dann heißt das nicht etwa, dass das System als Ganzes komplett ausgelastet ist. Vielmehr stehen mit den drei nicht zugewiesenen CPU-Kernen noch bis zu 75 Prozent der CPU-Leistung des Hostsystems insgesamt zur Verfügung.
Nur die zugewiesenen CPU-Ressourcen der virtuellen Instanz sind bei diesem Beispiel komplett ausgelastet und arbeiten somit am Limit. Teilweise lassen sich die Ressourcenverbraucher nicht so einfach zuordnen. Im normalen Einsatz kann es durchaus vorkommen, dass sich verschiedene VM-Systeme die jeweils zugewiesene CPU-Leistung teilen. Also meldet ein Messwert beim VM-01 beispielsweise 100 Prozent CPU-Last obwohl diese VM-01 nur einen Bruchteil der maximal zur Verfügung gestellten Ressourcen verbraucht, während VM-02 und VM-03 auch gerade fast unter Volllast laufen, und für die Maximalwerte von VM-01 mitverantwortlich sind. Diese Probleme sollten den meisten Administratoren geläufig sein, auch auf physikalischen Maschinen können solche Flaschenhälse unter Umständen auftreten, und werden hierunter dem Begriff „Context Switches“ zusammengefasst.
Hier kann es vorkommen, dass aufgrund ineffizienter Programmierung zu viele Threads mit gleich hoher Priorität parallel in der CPU abgearbeitet werden sollen, was bei bestimmten Situationen zu diesem Ping-Pong-Effekt führen kann.
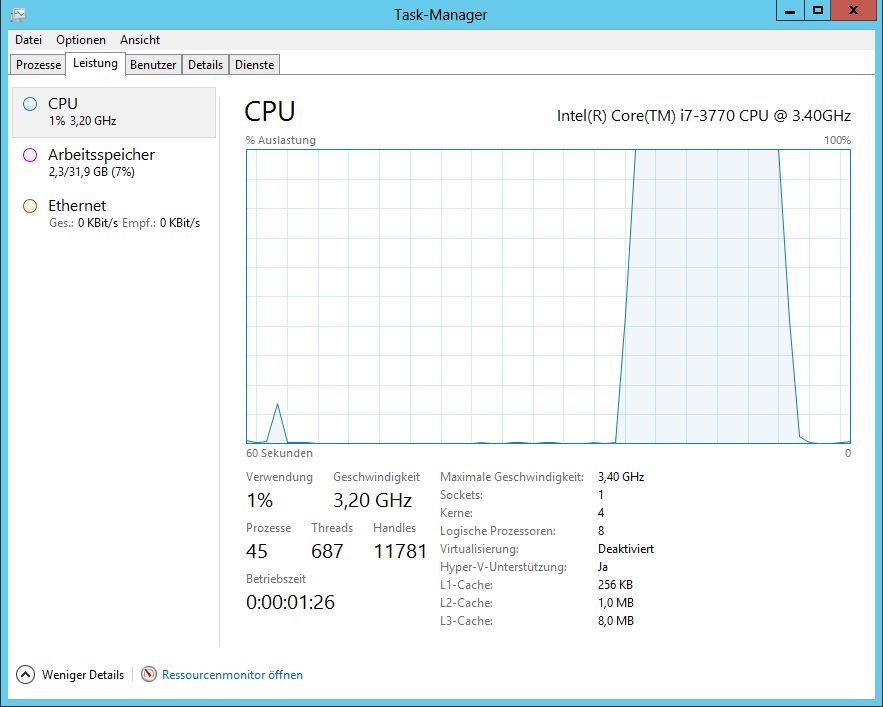
Ein anderer Gesichtspunkt bei Benchmark-Messungen stellt die Tatsache dar, das die jeweiligen Messwerte nur einen Schnappschuss der jeweiligen Situation liefern können, wie in Bild-1 dargestellt. Somit sind sogenannte Dauertests und Monitoring-Logfiles, die sich über Stunden oder Tage erstrecken, deutlich aussagekräftiger als ein relativ kurzes Performance-Logfile oder Benchmark Programm, das bereits nach einigen Minuten mit den jeweiligen Testende Messwerte präsentiert. Nur mit langfristig erhobenen Daten können folglich Aussagen daüber gemacht werden, ob sich normale Leistungsspitzen teilweise bis 100 Prozent Ressourcenverbrauch nur kurzfristig aufbauen, oder ob es sich dabei quasi um einen Dauerzustand handelt (siehe Bild 2).
Zusammenfassung
In der Diagnose von VM-Performanceproblemen sollte der Administrator immer auf objektive Messwerte verlassen. So können Vergleichswerte der VM mit geringer Gesamtperformance anderen Ergebnissen von VMs mit normalen Parametern gegenübergestellt werden. Damit erhält der Administrator eine sinnvolle Gesamtdarstellung und kann im weiteren Vorgehen eine positive oder negative Entwicklung sowie eine mögliche Stagnation frühzeitig voraussehen.
So kann ein Administrator beispielweise nach dem Verändern einzelner Parameter (wie etwa das Freigeben vom weiteren virtuellen Hauptspeicher oder das Hinzufügen von zusätzlichen CPU-Ressourcen) besser abschätzen, ob das gewählte Vorgehen in die richtige Richtung zielt. So kann er dann auch einzelne Maßnahmen richtig bewerten. Im zweiten Teil dieses Beitrages widmet sich das NT4ADMINS-Team einigen Maßnahmen und Einzelheiten, die helfen können, die Performance von Hyper-V-Systemen auf der Host- und VM-Seite positiv zu beeinflussen.
Drei-Punkte-Plan
Wie dieser Beitrag deutlich zeigte, warten bei der Fehlereingrenzung der VM-Performanceprobleme viele Fallstricke auf den Systembetreuer: Diese lassen sich mit dem NT4ADMINS Drei-Punkte-Plan aber gut umgehen:
- Punkt-1. Messwerte von physikalischen nicht mit denen von virtuellen Maschinen vergleichen!
- Punkt-2. Beleuchtung des Umfelds, wann treten Geschwindigkeitseinbrüche bei welchen VMs in was für einem Umfang auf?
- Punkt-3. Aussagekräftige Messwerte erfordern einen langen Beobachtungszeitraum, wie in Bild 3 mittels der Leistungsüberwachung dargestellt.


